
Do SEO and don’t think you need to know about JavaScript? Well John Mueller (Senior Webmaster Trends Analyst @ Google) disagrees. Everyone who does SEO should know about JS.
“You're going to run into significantly more JavaScript over the next years than in the 2-ish decades in SEO before. If you're keen on technical SEO, then past HTML you're going to need to understand JS more and more.”
JohnMu, Google: https://old.reddit.com/r/SEO/comments/98g82r/how_much_javascript_do_i_need_to_know_for_seo/
JavaScript was more popular in the past, especially in the days of Java applets, competing with Flash to add small dynamic elements to web pages. It wasn’t indexable by search engines and it wasn’t that huge a problem. Different web technologies tend to cycle out of use (much like Flash, which has all but disappeared), and JavaScript, too, appeared to be on the way out. However as HTML5 and CSS3 have risen in popularity so has JavaScript, within new frameworks such as Angular and React.
These frameworks are JS driven ways of creating webpages, which allow for a greater amount of dynamic content. Although Google insists they are quite capable of indexing JS the reality is a little different. This largely comes down to the inflexibility of JS rendering compared to HTML and CSS. In other words, the likelihood of a page not being able to be read in JS by Google is higher than a page in HTML / CSS.
As such, understanding the basics of how JS works or indeed might not work for Search Engines is a worthwhile exercise for any SEO or webmaster. So in this article let’s go through the basics of what it is, how it works and the most common reason for Google failing to index your JavaScript.
What is JavaScript?
JavaScript is a script based language which allows you to build highly interactive or dynamic web content. Or in other words, content which is dynamically updated. So as you interact with the content, it can change. This unlocks a whole world of functionality beyond what can be achieved with CSS and HTML.
For example a large part of Wordtracker is built with Angular (although we have in the past used other libraries such as React and Coffee.JS for different elements). This allows us to have the the keyword tool as part of the same application as the homepage. This gives us far greater flexibility in how these different parts of Wordtracker interact.
Yes, but how does it actually work?
This is where the DOM comes in. The Document Object Model is the representation of what you see on page as it is displayed in your browser. This might be very different from the page code, such as the HTML/CSS behind the page, as scripts and other dynamically updating content affect it. The DOM sits in the middle between the page code and what gets displayed.
The DOM
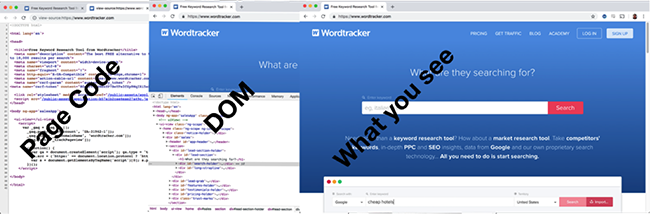
Within your browser you can use the ‘Inspect Element’ function (found in Chrome, Firefox, Edge) to see what the DOM looks like and change it yourself. Making changes here are reflected in the rendered version of the page you are shown.
JavaScript also makes changes to the DOM, meaning content displayed in your browser can continue to change after the page has initially loaded. So the DOM absolutely essential for JavaScript, as that’s what it interacts with, rather than with the code that generates that model.
So in short, JavaScript is a way of manipulating the DOM so you can change what is shown to the user in the browser.
JavaScript and SEO
It hasn’t always been the case that JavaScript would play nice with search engines. In fact many SEO’s still take that view. But Google, who has released its own JavaScript framework, Angular, as well as Bing and other search engines, have made great strides in indexing content within JavaScript.
Being able to recognise when content is built with JavaScript as well as some of the most frequent indexing errors may well pay dividends as it becomes increasingly common, as JohnMu is predicting.
Is this page JavaScript?
The biggest fundamental here is whether the page code looks different to the rendered page. For an easy example here is the Wordtracker homepage code:
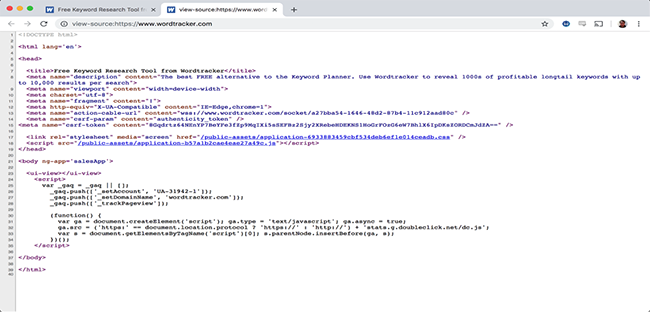
Comparing that to the actual page and using the Inspect Element feature to view the DOM shows that there is a lot of additional information here, which has to be coming from somewhere. We can also see that there is a .js script being run:
<script src="/public-assets/application-b57a1b2cae4eae27a49c.js"></script>
Where the page code is different from the page as displayed, there has to be something changing the DOM and it’s a pretty good bet that it’s going to be JavaScript.
Common Javascript problems for SEO
The main issue here is with crawling and rendering JavaScript content. So being able to see the content and then properly interpreting it. Or as Google says;
“Sometimes the JavaScript may be too complex or arcane for us to execute, in which case we can’t render the page fully and accurately.”
https://webmasters.googleblog.com/2014/05/understanding-web-pages-better.html
But really what they mean is, we’re not perfect. Saying ‘sometimes JavaScript is too complex’ is just another way of saying ‘sometimes our understanding of JavaScript isn’t good enough’. Although the statement is from 2014, it still holds true that sometimes they just won’t be able to get it quite right. So the first problem may well be that Google simply can’t index the content because the JavaScript it’s in is too complex.
Accessibility
Google doesn’t use the latest, greatest version of Chrome to render pages, it actually uses Chrome 41. We’re currently on version 70.X so it’s a little behind the rest of us. This means there may be functionality supported in a modern browser that Google’s older rendering technology cannot decipher.
“Googlebot uses a web rendering service (WRS) that is based on Chrome 41 (M41). Generally, WRS supports the same web platform features and capabilities that the Chrome version it uses”
So don’t assume that just because everything looks great in your browser that it does to Google as well. You’ll need to make sure critical content can be rendered in Chrome 41 and that graceful degradation is used to handle where it can’t and, just as importantly, when users do not have JavaScript enabled in their browser.
You can use the ‘Fetch as Google’ tool in your search console to see what the page looks like to Google and make sure that content is rendering as it should:
https://support.google.com/webmasters/answer/6066468?hl=en
Coding errors
Another issue comes from how JavaScript is loaded vs how flat HTML content is loaded. HTML is loaded as a single chunk, meaning that if there is an issue in one part of the document, the rest will still be accessible. In fact both Google and most browsers are pretty forgiving of HTML errors and will correct them for you.
Not so with Javascript. If you have an error then the script will fail and none of the content will be accessible. It’s a lot less forgiving so Google will miss the content and your rankings will suffer.
Look at this great case study about Hulu.com and how their JavaScript implementation has caused them to lose out massively in the rankings:
https://www.elephate.com/blog/javascript-seo-backfire-hulu-com-case-study/
Critical rendering path
The critical rendering path is the way pages are loaded so that the user has the lowest possible page loading time. This means critical assets are loaded first, so content above the fold appears the most quickly.
If your JavaScript is required to be loaded before the critical above the fold content, so a top heavy page with lots of big scripts which need loading early on, it’s going to block the rest of the content. This is known as ‘render-blocking JavaScript’.
Use tools such as Google Page Speed Insights to analyse the page and highlight errors such as this:
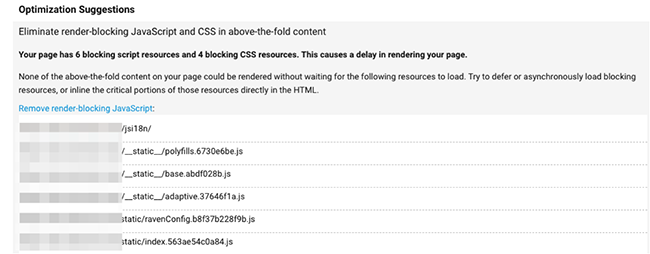
Google wants you only to load the vital stuff that’s needed for the above the fold content first, so the user ends up with the quickest possible experience.
5 seconds to go...
Google gives assets 5 seconds to load and that’s it. At that point it will stop waiting and move on to the next thing. This means if your JavaScript is slower than 5 seconds Google will have given up on it.
You also have to consider your ‘crawl budget’, the total amount of time and resource Google will allocate to crawling your site. All websites are not equal. The more popular your site the more generous Google will be with its crawl budget. If your server is slower to respond it will crawl fewer pages.
So, if you have lots of slow loading scripts and assets you will eat up your allocated budget more quickly resulting in fewer pages being crawled. Most likely the lower down or deeper pages, which may contain highly valuable long tail content, will be missed.
Stop blocking JavaScript
We all know the classic mistake of a website not getting indexed as someone has set the robots.txt to:
User-agent: *
Disallow: /
Well there is a very similar problem which happens with JavaScript. Classically, as a security measure, .js files have traditionally been blocked. However if it’s blocked, Google can’t render it, so therefore can’t see the content. This has a direct impact on how Google will rank your page.
If you are blocking Google from accessing your JavaScript files they will warn you within your Search Console.
In summary
Being a ‘technical SEO’ often involves more in-depth knowledge of how the web works and the different languages which are used to create websites. As some technologies such as JavaScript frameworks become more commonplace, it means it’s more likely to have an impact on everyday SEO.
Just as needing to know the basics of HTML and CSS is essential for SEO, knowing these basics for JavaScript is fast becoming essential as well. Writing this article I used a couple of great resources I would strongly recommend for further reading if you’re interested;
The Elephate Ultimate guide to JavaScript:
https://www.elephate.com/blog/ultimate-guide-javascript-seo/
Understanding objects in JavaScript:
https://www.digitalocean.com/community/tutorials/understanding-objects-in-javascript
What is the DOM:
https://www.w3.org/TR/WD-DOM/introduction.html
