
Talk to Books is Google’s latest AI offering and part of their new suite of ‘Semantic Experiences’. It gives you a way to search through the Google books project with, as Google boldly proclaims, “no dependence on keyword matching”.
So if Google has developed a new way of searching without using keywords, what does this mean for search moving forwards? It’s reasonable to assume that this is being developed ultimately to improve their core product, and so will be making its way across to search.
Keyword VS Semantic matching
Google states that it uses word vectors in order to learn about the relationship between keywords;
“Natural language understanding has evolved substantially in the past few years, in part due to the development of word vectors that enable algorithms to learn about the relationships between words, based on examples of actual language usage. These vector models map semantically similar phrases to nearby points based on equivalence, similarity or relatedness of ideas and language.”
https://research.googleblog.com/2018/04/introducing-semantic-experiences-with.html
Word Vectors
Specifically in this case they are using Word Vector models, or Vector Space Models (VSMs) which is way of plotting semantically linked words together and modelling their relationship with other words. This is done purely through repeated modelling of the context in which those words are used.
The innovation is creating vectors out of entire sentences rather than individual words as word2vec currently does. They’re going up a level: first use word2vec to vectorise words, then make a single vector representing all the word vectors making up a sentence.
The difference as to how a traditional keyword based search works is that the original phrase and the matching phrase do not necessarily need to contain the same words.
Let’s take the same query and look at the different ways it might be answered in the two techniques:
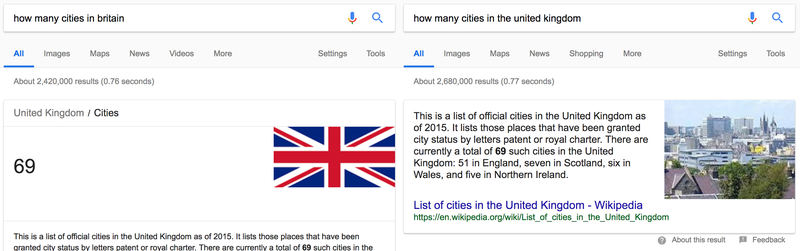
Query : “How many cities are in Britain?“
Possible answers:
- There are about 70 cities in Britain
- The United Kingdom has 69 cities
Keyword Matching would be most likely to answer “There are about 70 cities in Britain” as the query and the answer sentence share the highest % of information. They are the closest match.
Semantic matching, however, may well come up with a different answer: “In the United Kingdom there are 69 cities”, understanding the ‘United Kingdom’ to have the same meaning as ‘Britain’ so the query and resulting sentence become very closely matched.
Google has been working for some time to include more semantic meaning and information within the search algorithm. But you can see it still chooses to provide different results for questions which are semantically the same:
How Talk to Books does it
“In Talk to Books, when you type in a question or a statement, the model looks at every sentence in over 100,000 books to find the responses that would most likely come next in a conversation.”
https://research.google.com/semanticexperiences/about.html
It’s using the VSM’s it has built with those 100,000 or so books to model the information in a way that means it knows how words, sentences and phrases can be seen to relate to each other.
Digitising a huge corpus of published material has given Google access to pre-formatted, human edited content, with a far higher threshold of quality than content on the internet. This means the models constructed will work better and with a higher degree of certainty.
This is what makes the books project an excellent first step but also shows why it is a long way from being able to deal with the vastly larger, more complex and less structured content that is the World Wide Web.
Let’s look at some of the shortcomings of the current approach:

Simple questions often fail, even though the material does actually contain the information:

This is just because of the way the information is constructed. It doesn’t sit within a format the model sees as a fit for the query. Google has gone from matching keywords, to matching semantically linked words, to matching semantically linked sentences. But it’s still lacking actual understanding.
The problem with AI and Search
The illusion of intelligence and actual true intelligence are two very different things. If a computer was pre-programmed with a huge volume of pre-prepared answers to questions, you may be able to talk to it and for a time be tricked into thinking that it could understand what you were saying.
Of course, there is no understanding, it’s just matching your input to the pre-prepared output. Now if you wanted the computer to appear a little more clever you might want it to be able to answer questions which you had not thought of, but were similar to ones it had already been programmed for. So instead of needing to be asked word for word, the computer would give the same output for a range of questions that meant the same thing.
The more questions it was asked the more input it gets, so the better it gets at understanding which words and then phrases mean the same thing. The Vector Models are allowing Talk to Books to do this. In other words, to extend out from just trying to match a predefined input with a predefined output to being able to give a correct output based on an input it may have never encountered before.
Although this is broadly called ‘Artificial Intelligence’, it’s more really the Illusion of Intelligence. Google refers to Talk to Books in terms of AI and Natural Language Processing. The key difference is that it’s not an artificial version of what we understand to be intelligence, but rather an artificial way of making something look intelligent.
When the information given in the query is understood in its actual nature, so the format is no longer relevant and the information given in the output does not need to directly match the pre-defined outputs (currently the web results), then it would be getting a lot closer to actual intelligence.
An example would be the query:
“How many people were reported missing in Ontario in 1997?”
If there is no sentence that says ‘In 1997 X amount of people were reported missing’, or some variant of, then neither keywords or semantic matching will be able to find the answer. However if the nature of the question was understood….
- 1997 - Time frame
- Ontario - Place
- How many - Requires a numerical amount to answer
- People - The object of the sentence
- Missing - Change of state
With this, all the information is now there to understand what the question is actually asking. With that understanding every piece of information fitting into those parameters, about the same object and change in state (for example analysing the web to find every article where there is a report of a missing person) then an answer could be determined in the correct format…
{place} {time} {numerical value} {object} {state change}.
Ontario 1997 100 people missing
The closer we get to creating something that actually understands what we are asking then the closer we get to true Artificial Intelligence. Something which can take a set of information and ascertain new information from it would be a massive step forwards, but we’re not there yet.
Keywords and Search
Until AI gets to the point where the words used in either the information or the query, then it’s a moot point. Keywords will still be invaluable, whether as used directly to match queries and results or to build the models which do so semantically.
Wordtracker are already using Natural Language Processing within our toolsets and have been doing so for a little while. We not only power the ‘related terms’ within our main tool through NLP but also it’s an integral part of our Inspect tool.
We use a service called OpenCalais which is not only exceptionally good, but also one of the best programs available for free to the general public. If you are at all interested in Natural Language Processing then give it a try. You can take any webpage or content and it will interpret what the key pieces of information are, such as people and places, but also the theme of the content.
We use it to process a webpage and understand if the keywords used in key parts of the page for optimization match the content, as well as seeing if there are any keywords missing that provide a better match.
I’m personally excited to see what Google's next move is and just how they might incorporate this type of matching into the results. When we get to the point of a true ‘AI’ which can both understand the question and form new information from the provided material then we will likely see a complete paradigm shift in the way search engines work or if we use them at all.
After all, why would you need to use Google when you could just ask a question straight from your laptop, which then compiles the response from the world's information and gives you the answer - whether or not someone else has thought to write it down online first. That’s likely quite the way off though.
