I was listening to BBC Radio 4 program called 'The Force of Google' on how search engines influence our lives. Within this was a very insightful snippet from Amit Singh talking about why Google got the unprofessional hair result wrong. According to him it's because Google's just not that good at double negatives. I decided to have a dig into the search results to see just what he meant, and I found the results more than a little surprising.
So what is this ‘Unprofessional Hair’ thing about anyway?
In case you’re out of the loop a bit of a storm began to brew across social media a few weeks ago about the search term ‘Unprofessional Hairstyles’. This article from the Guardian newspaper sums it up:
Recently, an MBA student named Rosalia discovered something alarming: Googling “unprofessional hairstyles for work” yielded image results mainly of black women with natural hair, while searching for the “professional” ones offered pictures of coiffed, white women. Often the hairstyles themselves were not vastly different -- only the hair type and the wearer’s skin.
So why is this and what did Amit Sigh mean by his comment? Well, let's take a look at the results and figure out just what's happening.
Breaking down the results
The problem highlighted is within the Google Images results, which are less competitive than the main web results but are pulled through into the mixed content on the homepage. The logical place to start looking is actually at those image results and to go from there. To negate the effect of the attention around the search term I looked at examples posted at the time of the original controversy.
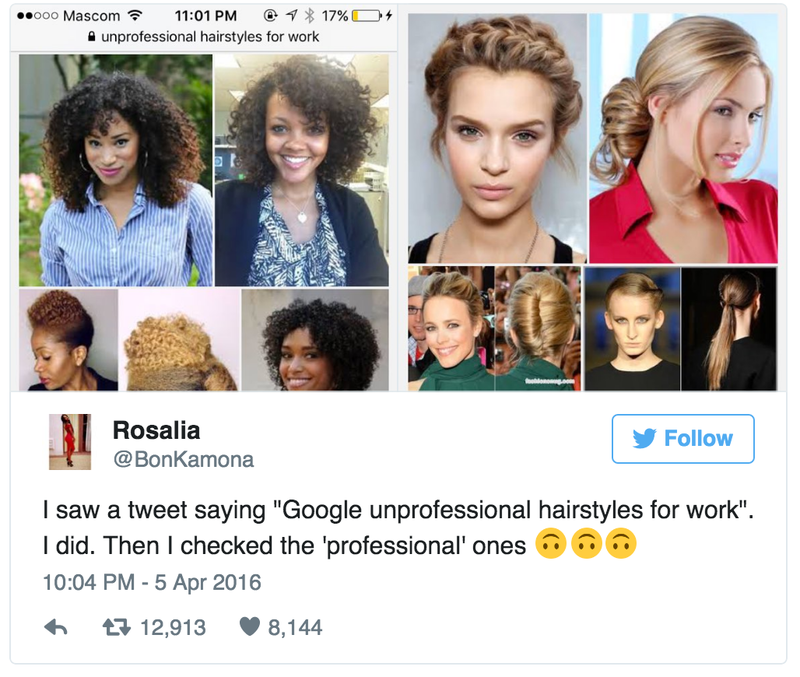
Looking at one of the tweets that started it all the image results are pretty much the same, with only a few changes caused by the recent attention around the search term. We can easily track down some of the original images and the pages they are on.
Here’s a great example for one of the most prominent images…
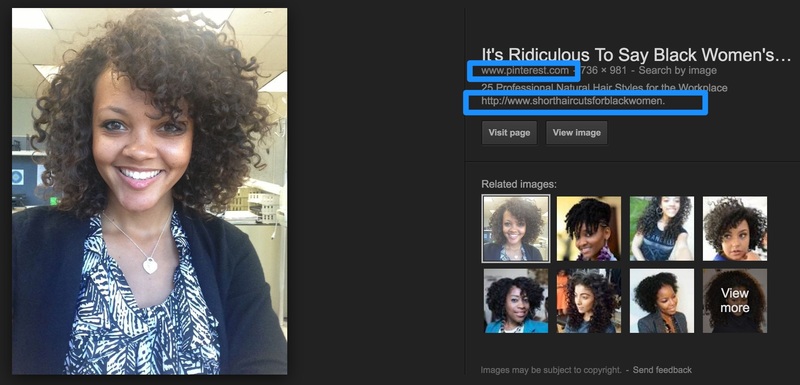
We can see it’s from Pinterest and also the page it was pinned from. Just looking at the Pinterest result shows some interesting information:
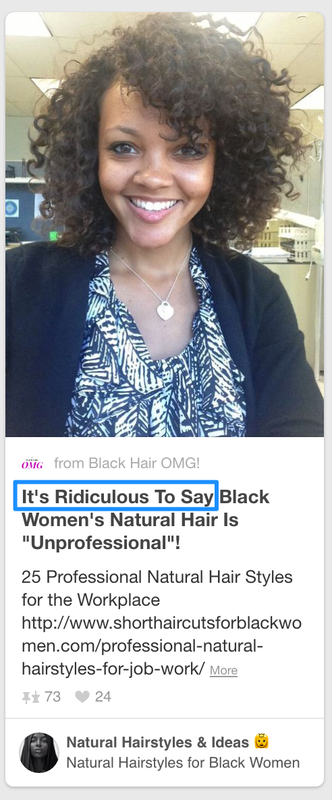
The article this is taken from is explaining how this type of haircut actually, and specifically, is not unprofessional. The article goes into a lot of detail on the subject.
You can see how Google might be breaking down the information it is seeing from the context of the words around it - and getting the wrong idea:
“It’s Ridiculous To Say Black Women’s Natural Hair Is “Unprofessional”!”
Google is grabbing the keywords used on page without looking properly at the content and so losing the meaning of those keywords. The further we dig and look at where the other images are pulled from the more this becomes apparent with many images being pulled from Pinterest via the same article.
So what does this tell us about Google?
Google is unable to understand the fundamental context of the page the information is being taken from or the meaning and intent of the search that provides those keywords. In other words it cannot connect the intentions of the person searching with the meaning of the content it is showing.
When you are searching for ‘Unprofessional Hairstyles’ what you are most likely looking for is examples of unprofessional hair. However Google is just giving you information ‘related to’ what you searched. Sure these images are closely related to the search in that they are from pages which use the same words, but the meaning is completely different.
Let’s take this a step further and search for ‘examples of unprofessional hair’.
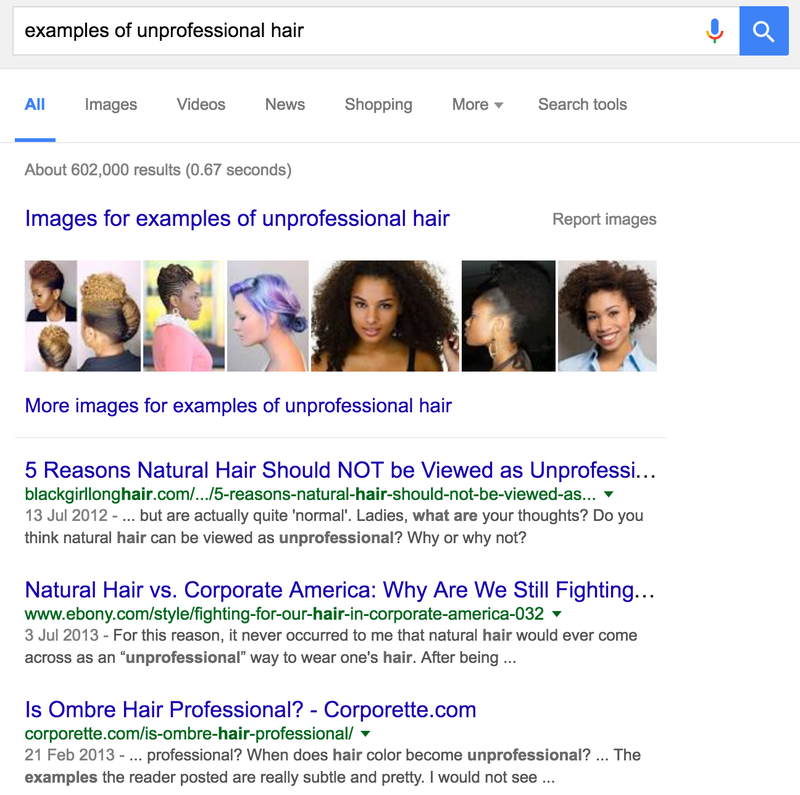
Even with that extra information, now clearly demonstrating intent, Google still appears to make the same error. Just look at the first result, it’s about how ‘natural hair should not be viewed as unprofessional’ or in other words - the article is about how it is professional. Google clearly can’t make that leap and is still just keyword matching. In fact let’s do something I haven’t done for a while. Let’s do a keyword density analysis on that top result:
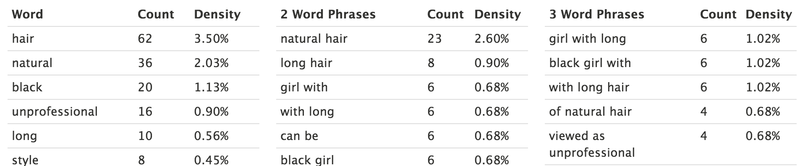
Clearly the result is being matched on keywords, not intent. What may be making the results even more skewed is that Google is trying to understand the context of the keywords that have been used by looking at the others used on page, without considering the double negative ‘is not’.
In summary
Google isn’t as advanced as we tend to think when it comes to natural language processing (taking spoken or written content and making it searchable). Their efforts are more focused on understanding what is in the content, rather than what it means. This is taken from Google's page on Natural Language Processing.
Our syntactic systems predict part-of-speech tags for each word in a given sentence, as well as morphological features such as gender and number. They also label relationships between words, such as subject, object, modification, and others. We focus on efficient algorithms that leverage large amounts of unlabeled data, and recently have incorporated neural net technology.
On the semantic side, we identify entities in free text, label them with types (such as person, location, or organization), cluster mentions of those entities within and across documents (coreference resolution), and resolve the entities to the Knowledge Graph.
http://research.google.com/pubs/NaturalLanguageProcessing.html
All of this is focused on the classification of content, much of it through identifying and building entities and then mapping the relationships between these. This is great if you want to google ‘takeaway pizza in south London’ (or even just shout it at your phone). However when looking for something a little more nuanced, we can all see Google still has a long, long way to go.
