
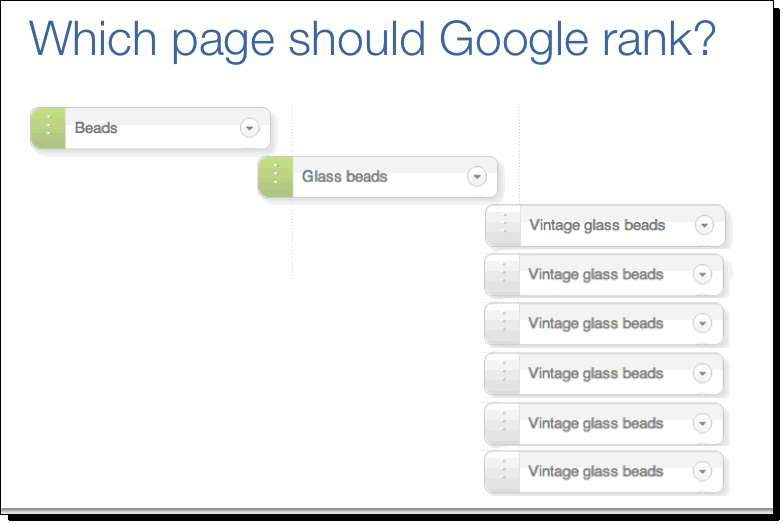
Duplicate content is a really bad thing.
If you have duplicate content on your site, Google doesn’t know which version of your page to rank.
Any links you get will be split between the different versions of the page. So, each of your duplicate pages is likely to rank badly.
And, as we know, badly ranking pages don’t attract traffic.
What are the common causes of duplicate content?
Well, most are technical. And they happen unintentionally. Often because your site’s developers aren’t aware of the SEO problems that duplicate content can cause.
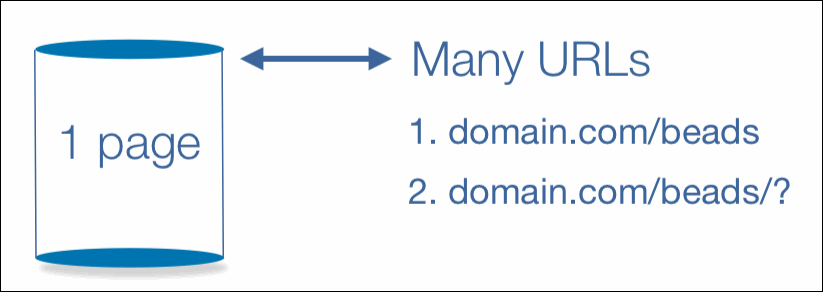
A developer might say that this page:
http://www.domain.com/beads/
is the same as this one:
http://www.domain.com/beads/?
But Google wouldn’t.
So, what’s happening?
Well that page is probably stored in a database that contains all the pages on our site. As far as the developer’s concerned, there’s only version of the page in the database.
Yet, it’s possible to access that page from a number of different URLs.
The ? at the end of the web address (URL) is often used as a way of adding a parameter, such as tracking code. For example, if you wanted to track an Event in Google Analytics you'd add a parameter.
Another common parameter might look like this:
http://www.domain.com/beads/?source=rss
That's an RSS feed. But, again, Google would treat it as a different URL from our original.
Different versions of your pages: www and non-www
Another version of the problem occurs when there are www and non-www versions of a page.
And also when there’s http: and https: versions of a site.
While the content for these pages might be the same, and all these pages may work perfectly well from a visitor’s perspective, it's possible that Google may see each of these pages as duplicate content.

Session IDs
Another reason for duplicate content is a session ID.
A session ID is a way of managing the information you collect about your site's visitors. For example, if you’re running an ecommerce site you’ll want to keep track of your visitors and make it possible for them to store items in a shopping cart while they continue to browse your site. To do that, you need to give them their own “session” on your site.
Which is simply a brief summary of what the visitor’s done while they’ve been on your site.
Some ecommerce websites add Session IDs to the URL. Which means that every visitor has their own unique URLs: all duplicate content.
When a visitor links to or shares your content, they'll share one of their unique URLs, which means the lovely link juice will be spread over multiple pages - and your site will see little benefit.
Nowadays, most e-commerce systems allow you to remove Session IDs from your URLs. To fix this problem, you just need to change your settings.
Paginated pages
In some CMS systems - including WordPress - it’s possible to paginate longer posts, or comment pages.
But, again, this creates a problem of duplicate pages. You’ll start creating duplicate URLs that end like this.

If you find you’re creating duplicate comment pages in Wordpress, make sure you disable that feature in your settings. This should fix the problem.
Duplicate content is common, very common
Duplicate content is a common problem.
But, how do you know if your site’s suffering from it?
Well, we turn to our friend Google. A quick search will tell us.
We’ll need to use two advanced operators. We’ll search within our site using the site: search.
We’ll then add the title of the page that we want to know about.
So our search looks like this:
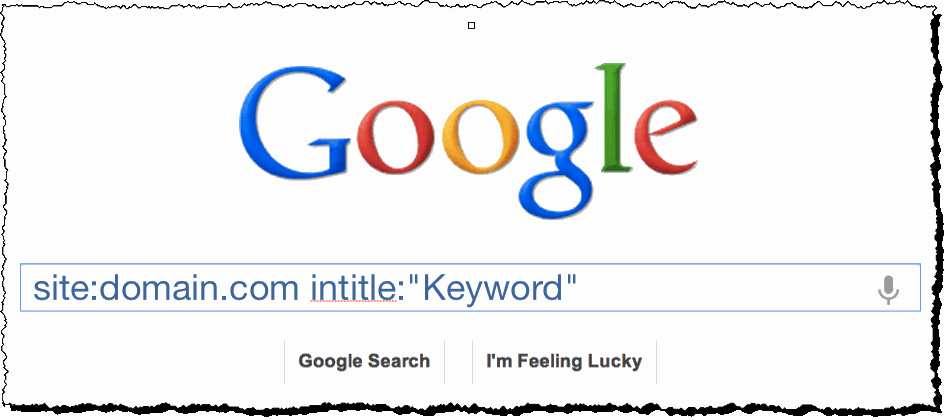
Note that there’s no space between the colon and the search term.
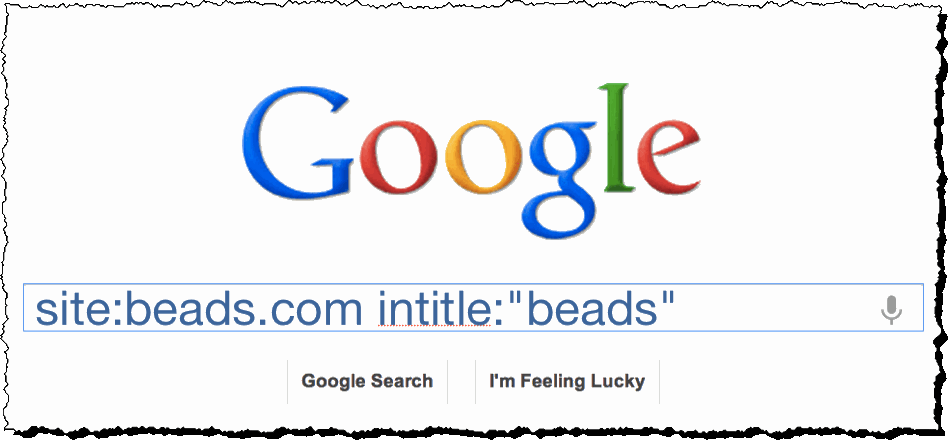
If we were searching beads.com for our 'beads' page, we’d search like this: site:beads.com intitle:"beads"
Another way of identifying duplicate content is to check your Google Webmaster Tools account.
If you look under "Optimization" you'll see "HTML Improvements"
Click "Duplicate Title Tags" and almost certainly you’ll discover duplicate content you had no idea existed.

Setting up Webmaster Tools is pretty simple. If you’re doing it for the first time you’ll find help here: How to set up Google Webmaster Tools
Canonicalization and dynamic content
So how do we solve these problems?
The fact is that, on our site, any of these might be the ‘correct’ URL; the one we’d like visitors to see - and link to.
http://www.domain.com/beads
http://domain.com/beads/
http://www.domain.com/beads.html
We call the ‘correct' version the canonical URL.
And if you’ve got duplicate content problems you’ll need to start a process of canonicalization.
Which doesn’t involve joining the priesthood. It’s just a few steps you can take to make sure Google’s indexing your site in the way you want.

Don't create duplicate content
Our first step is simply not to create duplicate content. And we’ve already mentioned some of the possible remedies.
Choose www or non-www
When you’re setting up your site you should choose between www and non-www addresses and stick to creating all your URLs in the same format.
Add redirects
If you’ve got both versions on your site, you’ll want to add redirects - click here for a Guide to Redirects
There are two common types of redirect: a 301 redirect and a 302 redirect.
The 301 redirect is permanent and will pass on most of your lovely link juice. So, that’s the one we’ll want to use. All it does is redirect one page to another. So, when you click on this URL ...
www.wordtracker.com/trial
... for instance, you’ll get redirected to this page:
https://keywords.wordtracker.com/signup
WordPress redirect plugin
In WordPress, there’s a plugin that will allow you to create your own 301 redirects.
Otherwise, you may have to ask your developer to set up your redirects.
There are tools you can use for checking whether redirects are in place, or a site audit will also show you.
And, if you just want to check out a single page, it’s worth using Rex Swain’s http header checker
This is a simple free tool that will tell you whether a page has been redirected. And where it’s been redirected to.
Canonicalization
Finally, it’s worth mentioning canonical links.
Occasionally, you’ll have duplicate versions of a page but you won’t want to add a permanent redirect.
To solve that problem, you can add a canonical link element. This simply lets Google know which is the correct (or canonical) version of our beads page:
We want this page to rank well: http://www.domain.com/beads/
So, we’d add this link to the head section of any duplicate pages:
<link rel="canonical" href="http://www.domain.com/beads/"/>
This lets Google know which page we want to list in its results.
Google then transfers most of the link value gathered by the duplicate page to your canonical page.
Problem solved
As we’ve mentioned, duplicate content issues occur on most sites. And we've seen that duplicate content can have many causes:

The effects of duplicate content can be serious - sites with duplicate content problems often suffer terrible traffic losses.
Luckily, it’s a problem that’s fixable - and the rewards can be substantial. By pooling your link juice it’s possible your pages can shoot up the rankings.
Free Trial of Wordtracker's Keywords Tool
Once you've fixed your duplicate content you can get back to the important job of finding relevant keywords. The more you rank well for, the more business you will do.
Start researching keywords today with a free 7-day trial of Wordtracker's Keywords tool