This week we’ve been extra busy making great progress on the new keyword tool. Whilst a lot of that has been implementing key functionality which is already available in the existing tool we’ve also been looking at a few changes to some key parts.
Before I go into the part where we really need your input to move forwards I’ll share a behind the scenes look at something we have been working on.
Finding related keywords
We’ve noticed that related keywords were getting less related, this is down to the way they are calculated and the systems we use to create them changing over time. So it was time for a complete overhaul of how they are generated.
Related terms are becoming increasingly important as Google places more importance in the context of keywords, whether they are related to the page as a whole. Words which are semantically linked help add more weight to the relevance of those terms to the content.
The trouble with finding related terms is that there is no easy way of doing. Google themselves has struggled with doing this accurately for a number of years and there is no API or quick fix solution out there (if there is and we’ve missed it I definitely want to know so if you know one let me know in the comments!).
Instead we have created our own mechanism for finding related terms using a combination of data sources and word crunching. This involves a few different methods such as finding synonyms and identifying similar words through a lexicon.
Where a keyword is a single word this can be done pretty easily by identifying synonyms. So any closely related terms can be shown:
The thing is, keywords are often made up of several words, such as ‘luxury hotels in france’ and this creates a much more complex problem. First off there is no way of treating the sentence as a whole, there is nothing to match it against. The only way forwards is to break it down into its constituent parts. So the first thing to do is to remove all the stop words.
Now we need to break the sentence down and find synonyms for the individual terms...
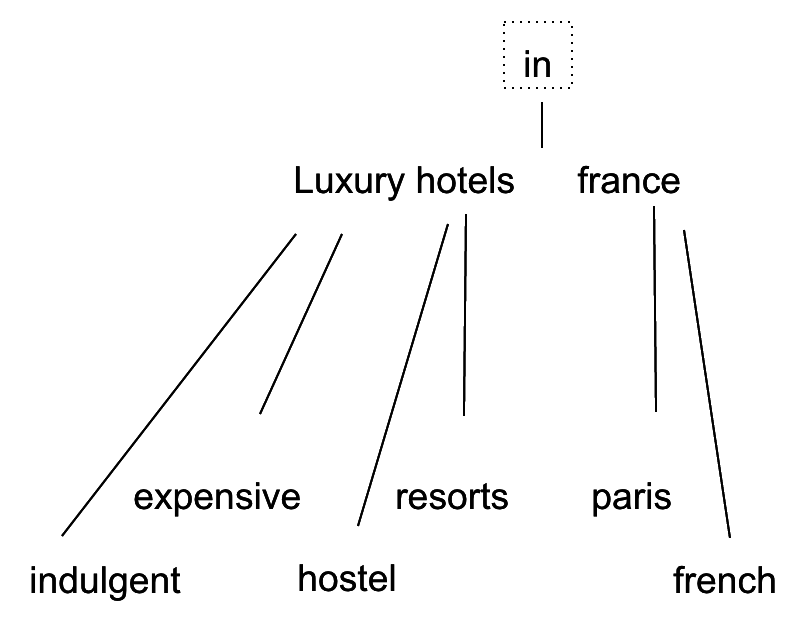
With this complete we can then go on to reconstruct the sentence from the various combinations of synonyms and put the stop word back in.

Taking this we then need to further refine it to find which are common phrases which a human would actually use. This is where having a 3.5 million keyword database comes in handy. So can match these against the Wordtracker keyword data and find which ones are actual keywords.
This is where we need your input - changing the way we show results
Understanding how people use Wordtracker is important as it allows us to make changes to the tool that make it easier to use. One of the features we know is popular is lists. This allows you to compile a number of different keyword searches into a single set of results.
We want to keep lists, but it has got us thinking that perhaps when drilling down into a search, clicking on keywords to search again with those terms, we should retain the original search's keywords as well.
This would mean that each time you drill down into a keyword you are increasing the searches for the term, allowing you to compile a large list which you can then filter to get the ideal keywords. From my own experience I like generating a large list by compiling multiple searches and then filtering this to find my ideal terms.
By allowing this happen right from the search page it would speed up this process considerably, improving the user workflow.
Keep it as it is or add new terms into the original results?
This is where we really want your input - what do you think about this change? Is this something that would suit your workflow or are you cringing at the thought?
Let us know in the comments or drop us a line directly at support@wordtracker.com or on @wordtracker on Twitter. Whatever your thoughts are on this we want to know your opinion.
